 0 Comments
0 CommentsLast Wednesday, October 30, undergraduate and graduate students gathered in Hamilton 702 to attend the “Introduction to Computational Biology,” hosted by Systems Biology Initiative.
The “Introduction to Computational Biology” workshop explored how computational tools are transforming genomic research. Led by student speakers Evelyn T., a Barnard sophomore specializing in computational biology; Margaret Hitt, a SEAS freshman studying biomedical engineering; and Nicholas Djedjos, a SEAS junior and co-president of the Systems Biology Initiative studying computer science, guided attendees through key questions at the intersection of biology and computer science.
The session kicked off with a compelling question: Why Computational Biology? Nicholas explained, “Biology is pretty unordered… but computer science is very selective.” The structured, data-driven approach of computer science, he noted, helps make sense of the complexity within biological systems.
The workshop covered foundational concepts in computational biology, beginning with techniques such as Polymerase Chain Reaction (PCR) and Gel Electrophoresis, essential for amplifying and analyzing DNA strands. The presenters highlighted PCR’s three steps—denaturation, annealing, and extension—explaining how these steps enable DNA replication, crucial for genetic research.
Another highlight was CRISPR, a powerful tool for editing genes. The speakers explained that CRISPR is inspired by a natural defense system in bacteria. By using RNA to target and cut specific DNA sequences, it enables precise modifications, which could potentially help treat genetic disorders like sickle cell disease.
Attendees were also introduced to RNA sequencing (RNA-seq), a process that allows researchers to detect known and novel features by analyzing RNA produced during transcription. RNA-seq is especially critical as it allows researchers to identify which genes are active under various conditions.
The discussion moved to data analysis techniques, with an emphasis on dimensionality reduction methods like PCA (Principal Component Analysis) and UMAP (Uniform Manifold Approximation and Projection). These tools simplify complex datasets, allowing researchers to visualize gene relationships and expression patterns across different cells.
Nicholas then shared insights on various computational techniques for proteins. He discussed the Basic Local Alignment Search Tool (BLAST), which finds regions of similarity between biological sequence and calculates the statistical significance of a homologous (similar) sequence. BLAST is particularly useful in clinical research, where treatments developed in model organisms might be applied to human models.
The highlight of the protein analysis discussion was AlphaFold, the groundbreaking deep-learning model for predicting 3D protein structures. Nicholas demonstrated how AlphaFold works, using a GenBank file containing the coding sequence for the hemoglobin subunit beta (HBB). By translating this sequence and feeding it into AlphaFold, attendees saw a high-accuracy prediction of the protein’s structure, showcasing the model’s transformative potential for drug discovery and disease research.
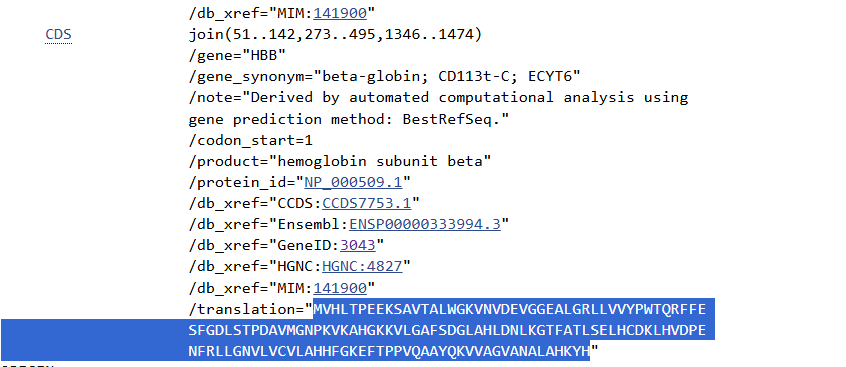
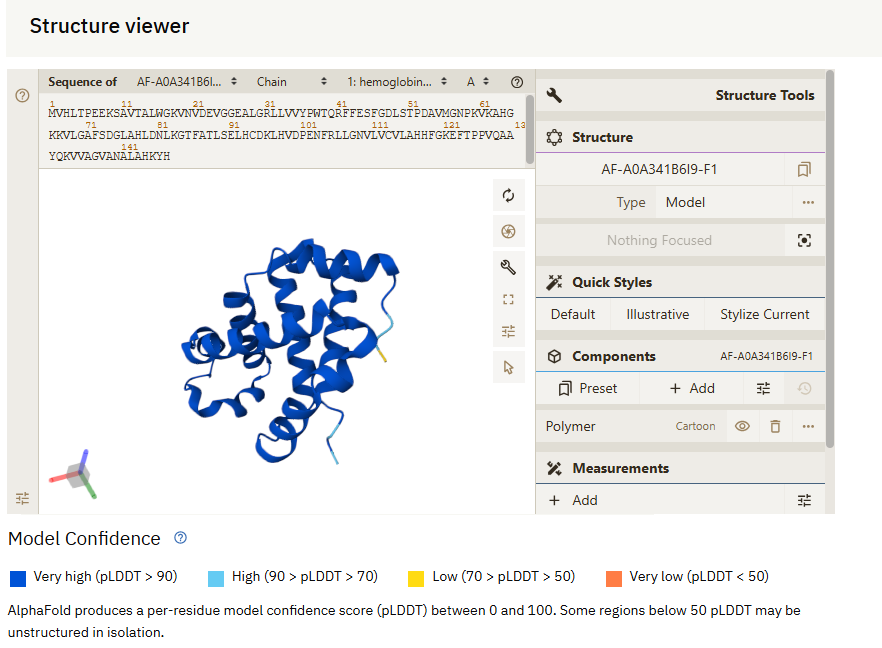
The session wrapped up with an open Q&A, where students discussed the usefulness of AlphaFold and important considerations to using it, such as where is the base environment. Further, speakers suggested resources from Professors such as Mohammed AlQuraishi, Elham Azizi, and It’sk Pe’er, all of whom do computational work.
Nicholas encouraged attendees to dive deeper into the field, emphasizing the range of accessible resources and beginner-friendly platforms for anyone interested in combining coding with biology. While biology and computer science are complex, the complementary strengths of these fields offer great potential for advancing research and medicine.
AlphaFold Screenshot via Author
Introduction to Computational Biology Event via Author
